24th August 2018 5:08 am
Machine Learning on a Commodore 64 (part 2)

If you’ll recall my first post on this subject you’ll remember I had wanted to start with coding a perceptron into a Commodore 64 emulator. Tonight, I tried to bring my mad experiment to life.
So, because I had absolutely no faith in my skills in BASIC V2 I wrote this code and tested it piecemeal. Write a little, run a little. With that in mind, I transcribed the first bit of my notepad code to the emulator:

And the result?

Not exactly a huge surprise. First off, it’s not “STEP:NEXT”, it’d just be “NEXT I” to denote a new I to continue the loop. With that fix the initialization of the bias and weights was put into place, now I could get focused on the data input. For the simplicity of the program, the data is user-defined.
I have it set up such that this has 6 nodes. The input has to be written as “010101” with quotes included. The numbers can be anything, but I tested with 1s and 0s. The code’s meant to take these 6 numbers as a string then break it up later into an array of 1 character strings that can be evaluated. Thus, the input was coded (with some effort, the name of the variable had to be changed. BASIC V2 isn’t fond of fancy variable names).
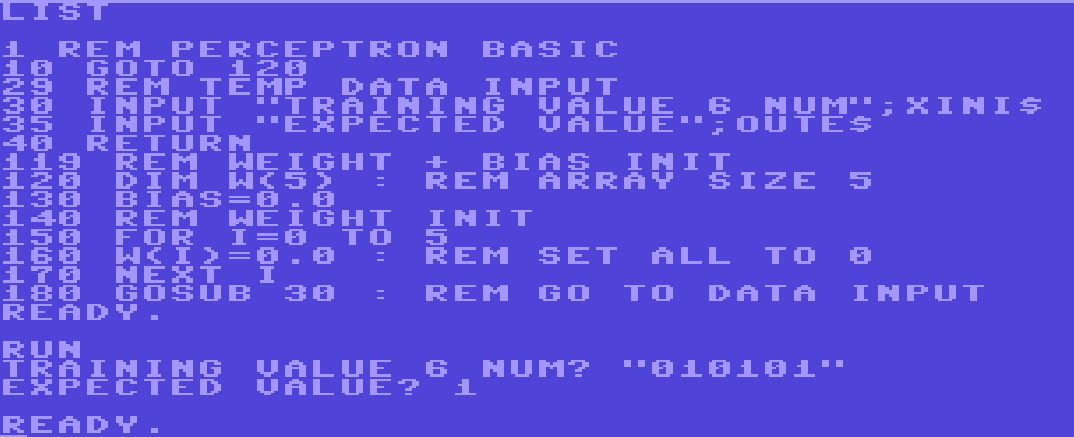
So, the input is a subroutine above the rest of the code. The idea is that I can take that block of code between 1 and 119 and make it into whatever I want later, so long as something is put in XINI$ and OUTE.
The next snag came from trying to actually break up the XINI$ string. The obvious choice was to use MID(x,y,z), which takes a string, x, and returns z characters starting at position y. So we could take our string, XINI$ as x, and iterate I from 0 to 5 to be our y, with z remaining as 1 so we can get each character one at a time. Except, woah there, cowboy. We run into another problem.

Type mismatch? What type mismatch? X$ is a string array. XINI$ is a string, so what’s the issue? Well, turns our MID(x,y,z) is for real numbers. If you want to do strings, you have to use MID$(x,y,z).

Even after figuring THAT out, there’s another issue of an illegal quantity. This isn’t an array index going out of range, that’d come up as “BAD SUBSCRIPT”, this is something different. I started a new instance of the emulator to test the DIM X(Y) command to see how it worked.

As expected, it’s 0-indexed. DIM X(50) has an index range of 0 to 50. Here you see I made an array of size 50 and show just that. X(99) and X(51) throw errors. So what’s the problem? Oh, just everyone’s favorite: Inconsistent array indexing. See, while calling a value from a DIM’d array is 0-indexed (ie X(0) is the first value), the MID(x,y,z) function decided to throw consistency to the wind and has the starting position value, y, be 1 indexed (ie MID(X,1,1) refers to the first value and MID(X,0,1) throws an error).

So, fine, have the for loop start from 1 and go to 6. Except X$, the array we’re breaking the string into, has to use I, too. So, no big deal, just do X$(I-1) instead, that’ll fix it, right? Well, yes, assuming you can find the subtraction symbol. This will probably be less of a problem on a real machine, but it can be a hassle on emulator.

The formula above LOOKS right, but it produces incorrect output. Why? Because that’s not I-1. That’s I[Horizontal Line]1. For those not in the know, the Commodore 64 keyboard has a lot of keys and functions that don’t exist on a modern keyboard. This includes several graphical symbols that were used mostly to make graphics for games or for formatting documents. You’d draw out borders using line characters. Thing is, these line characters can look awfully similar to minus symbols if you’re not careful.

So finally we have our input broken down and we can move on. Next, we focus on the code that actually calculates the system’s answer given an input. Reading off of its weights and biases:

Which results in…

Once again I’m getting too fancy with these variable names. X, Y and Z variables never killed anyone, I suppose. The lack of room for comments makes it even worse, this’ll be hard to understand in the future. Total is now Y. I go ahead and change ‘ANSWER’ to Z.
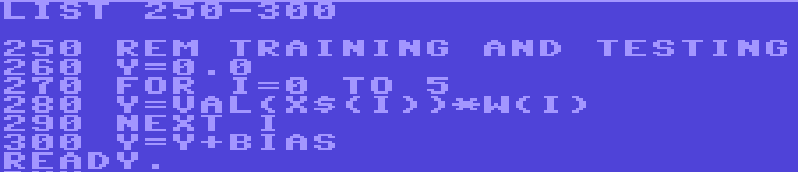
Finally, we can zip through the code for updating the biases. Following the Perceptron algorithm, it only updates the weights if the answer was wrong. IE if OUTE != Z. Granted, the weights might be updated even if the system got the problem right if OUTE = 2 (which means we’re testing). This can be fixed in future.

Running this, everything seems to be working fine until we attempt another pass of data, where we run into this:

Right, I had read this, a DIM’d array can’t be re-DIM’d. So, who says we can’t just DIM X$ once at the top of the code? Every pass-through it gets completely overwritten anyway. With that last touch, the program runs in full:
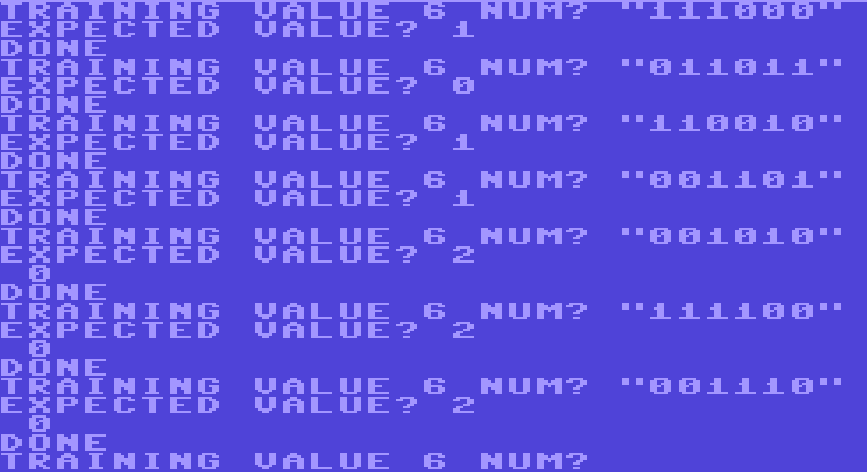
Is it really learning? It’s hard to say. It got its training examples 2/3, though it could just be outputting 0 every time. Print statements are kind of a pain on these old systems, which I’m sure is easy to see. Next time we’ll dig deeper into this thing and see what we can improve. Namely, we’ll try to add some metric in order to keep track of how well our C64 Perceptron is doing as more data is added. In addition, a new Data entry method is required. We’ll also need PRINT statements to see if there’s any errors under the hood.
I’ll be throwing up my CCS64 Savestate onto github along with my BASIC code in a txt document into a repository on GitHub.
~Nicko
